- Almacén de datos
-
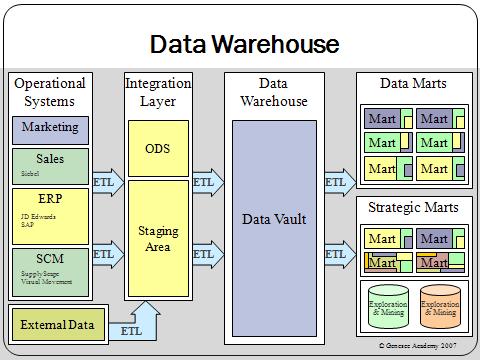
 Descripción de un Data Warehouse.
Descripción de un Data Warehouse.
En el contexto de la informática, un almacén de datos (del inglés data warehouse) es una colección de datos orientada a un determinado ámbito (empresa, organización, etc.), integrado, no volátil y variable en el tiempo, que ayuda a la toma de decisiones en la entidad en la que se utiliza. Se trata, sobre todo, de un expediente completo de una organización, más allá de la información transaccional y operacional, almacenado en una base de datos diseñada para favorecer el análisis y la divulgación eficiente de datos (especialmente OLAP, procesamiento analítico en línea). El almacenamiento de los datos no debe usarse con datos de uso actual. Los almacenes de datos contienen a menudo grandes cantidades de información que se subdividen a veces en unidades lógicas más pequeñas dependiendo del subsistema de la entidad del que procedan o para el que sean necesario.
Definiciones de almacén de datos
Definición de Bill Inmon
Bill Inmon[1] fue uno de los primeros autores en escribir sobre el tema de los almacenes de datos, define un data warehouse (almacén de datos) en términos de las características del repositorio de datos:
- Orientado a temas.- Los datos en la base de datos están organizados de manera que todos los elementos de datos relativos al mismo evento u objeto del mundo real queden unidos entre sí.
- Variante en el tiempo.- Los cambios producidos en los datos a lo largo del tiempo quedan registrados para que los informes que se puedan generar reflejen esas variaciones.
- No volátil.- La información no se modifica ni se elimina, una vez almacenado un dato, éste se convierte en información de sólo lectura, y se mantiene para futuras consultas.
- Integrado.- La base de datos contiene los datos de todos los sistemas operacionales de la organización, y dichos datos deben ser consistentes.
Inmon defiende una metodología descendente (top-down) a la hora de diseñar un almacén de datos, ya que de esta forma se considerarán mejor todos los datos corporativos. En esta metodología los Data marts se crearán después de haber terminado el data warehouse completo de la organización.
Definición de Ralph Kimball
Ralph Kimball[2] es otro conocido autor en el tema de los data warehouse, define un almacén de datos como: "una copia de las transacciones de datos específicamente estructurada para la consulta y el análisis". También fue Kimball quien determinó que un data warehouse no era más que: "la unión de todos los Data marts de una entidad". Defiende por tanto una metodología ascendente (bottom-up) a la hora de diseñar un almacén de datos.
Una definición más amplia de almacén de datos
Las definiciones anteriores se centran en los datos en sí mismos. Sin embargo, los medios para obtener y analizar esos datos, para extraerlos, transformarlos y cargarlos, así como las diferentes formas para realizar la gestión de datos son componentes esenciales de un almacén de datos. Muchas referencias a un almacén de datos utilizan esta definición más amplia. Por lo tanto, en esta definición se incluyen herramientas para la inteligencia empresarial, herramientas para extraer, transformar y cargar datos en el almacén de datos, y herramientas para gestionar y recuperar los metadatos.
Función de un almacén de datos
En un almacén de datos lo que se quiere es contener datos que son necesarios o útiles para una organización, es decir, que se utiliza como un repositorio de datos para posteriormente transformarlos en información útil para el usuario. Un almacén de datos debe entregar la información correcta a la gente indicada en el momento óptimo y en el formato adecuado. El almacén de datos da respuesta a las necesidades de usuarios expertos, utilizando Sistemas de Soporte a Decisiones (DSS), Sistemas de información ejecutiva (EIS) o herramientas para hacer consultas o informes. Los usuarios finales pueden hacer fácilmente consultas sobre sus almacenes de datos sin tocar o afectar la operación del sistema.
En el funcionamiento de un almacén de los datos son muy importantes las siguientes ideas:
- Integración de los datos provenientes de bases de datos distribuidas por las diferentes unidades de la organización y que con frecuencia tendrán diferentes estructuras (fuentes heterogéneas). Se debe facilitar una descripción global y un análisis comprensivo de toda la organización en el almacén de datos.
- Separación de los datos usados en operaciones diarias de los datos usados en el almacén de datos para los propósitos de divulgación, de ayuda en la toma de decisiones, para el análisis y para operaciones de control. Ambos tipos de datos no deben coincidir en la misma base de datos, ya que obedecen a objetivos muy distintos y podrían entorpecerse entre sí.
Periódicamente, se importan datos al almacén de datos de los distintos sistemas de planeamiento de recursos de la entidad (ERP) y de otros sistemas de software relacionados con el negocio para la transformación posterior. Es práctica común normalizar los datos antes de combinarlos en el almacén de datos mediante herramientas de extracción, transformación y carga (ETL). Estas herramientas leen los datos primarios (a menudo bases de datos OLTP de un negocio), realizan el proceso de transformación al almacén de datos (filtración, adaptación, cambios de formato, etc.) y escriben en el almacén.
Data marts
Los Data marts son subconjuntos de datos de un data warehouse para áreas especificas.
Entre las características de un data mart destacan:
- Usuarios limitados.
- Área especifica.
- Tiene un propósito especifico.
- Tiene una función de apoyo.
Cubos de información
Los cubos de información o cubos OLAP funcionan como los cubos de rompecabezas en los juegos, en el juego se trata de armar los colores y en el data warehouse se trata de organizar los datos por tablas o relaciones; los primeros (el juego) tienen 3 dimensiones, los cubos OLAP tienen un número indefinido de dimensiones, razón por la cual también reciben el nombre de hipercubos. Un cubo OLAP contendrá datos de una determinada variable que se desea analizar, proporcionando una vista lógica de los datos provistos por el sistema de información hacia el data warehouse, esta vista estará dispuesta según unas dimensiones y podrá contener información calculada. El análisis de los datos está basado en las dimensiones del hipercubo, por lo tanto, se trata de un análisis multidimensional.
A la información de un cubo puede acceder el ejecutivo mediante "tablas dinámicas" en una hoja de cálculo o a través de programas personalizados. Las tablas dinámicas le permiten manipular las vistas (cruces, filtrados, organización, totales) de la información con mucha facilidad. Las diferentes operaciones que se pueden realizar con cubos de información se producen con mucha rapidez. Llevando estos conceptos a un data warehouse, éste es una colección de datos que está formada por «dimensiones» y «variables», entendiendo como dimensiones a aquellos elementos que participan en el análisis y variables a los valores que se desean analizar.
Dimensiones
Las dimensiones de un cubo son atributos relativos a las variables, son las perspectivas de análisis de las variables (forman parte de la tabla de dimensiones). Son catálogos de información complementaria necesaria para la presentación de los datos a los usuarios, como por ejemplo: descripciones, nombres, zonas, rangos de tiempo, etc. Es decir, la información general complementaria a cada uno de los registros de la tabla de hechos.
Variables
También llamadas “indicadores de gestión”, son los datos que están siendo analizados. Forman parte de la tabla de hechos. Más formalmente, las variables representan algún aspecto cuantificable o medible de los objetos o eventos a analizar. Normalmente, las variables son representadas por valores detallados y numéricos para cada instancia del objeto o evento medido. En forma contraria, las dimensiones son atributos relativos a las variables, y son utilizadas para indexar, ordenar, agrupar o abreviar los valores de las mismas. Las dimensiones poseen una granularidad menor, tomando como valores un conjunto de elementos menor que el de las variables; ejemplos de dimensiones podrían ser: “productos”, “localidades” (o zonas), “el tiempo” (medido en días, horas, semanas, etc.), ...
Ejemplos
Ejemplos de variables podrían ser:
- Beneficios
- Gastos
- Ventas
- etc.
Ejemplos de dimensiones podrían ser:
- producto (diferentes tipos o denominaciones de productos)
- localidades (o provincia, o regiones, o zonas geográficas)
- tiempo (medido de diferentes maneras, por horas, por días, por meses, por años, ...)
- tipo de cliente (casado/soltero, joven/adulto/anciano, ...)
- etc.
Según lo anterior, podríamos construir un cubo de información sobre el índice de ventas (variable a estudiar) en función del producto vendido, la provincia, el mes del año y si el cliente está casado o soltero (dimensiones). Tendríamos un cubo de 4 dimensiones.
Elementos que integran un almacén de datos
Metadatos
Uno de los componentes más importantes de la arquitectura de un almacén de datos son los metadatos. Se define comúnmente como "datos acerca de los datos", en el sentido de que se trata de datos que describen cuál es la estructura de los datos que se van a almacenar y cómo se relacionan.
El metadato documenta, entre otras cosas, qué tablas existen en una base de datos, qué columnas posee cada una de las tablas y qué tipo de datos se pueden almacenar. Los datos son de interés para el usuario final, el metadato es de interés para los programas que tienen que manejar estos datos. Sin embargo, el rol que cumple el metadato en un entorno de almacén de datos es muy diferente al rol que cumple en los ambientes operacionales. En el ámbito de los data warehouse el metadato juega un papel fundamental, su función consiste en recoger todas las definiciones de la organización y el concepto de los datos en el almacén de datos, debe contener toda la información concerniente a:
- Tablas
- Columnas de tablas
- Relaciones entre tablas
- Jerarquías y Dimensiones de datos
- Entidades y Relaciones
Funciones ETL (extracción, transformación y carga)
Los procesos de extracción, transformación y carga (ETL) son importantes ya que son la forma en que los datos se guardan en un almacén de datos (o en cualquier base de datos). Implican las siguientes operaciones:
- Extracción. Acción de obtener la información deseada a partir de los datos almacenados en fuentes externas.
- Transformación. Cualquier operación realizada sobre los datos para que puedan ser cargados en el data warehouse o se puedan migrar de éste a otra base de datos.
- Carga. Consiste en almacenar los datos en la base de datos final, por ejemplo el almacén de datos objetivo normal.
Middleware
Middleware es un término genérico que se utiliza para referirse a todo tipo de software de conectividad que ofrece servicios u operaciones que hacen posible el funcionamiento de aplicaciones distribuidas sobre plataformas heterogéneas. Estos servicios funcionan como una capa de abstracción de software distribuida, que se sitúa entre las capas de aplicaciones y las capas inferiores (sistema operativo y red). El middleware puede verse como una capa API, que sirve como base a los programadores para que puedan desarrollar aplicaciones que trabajen en diferentes entornos sin preocuparse de los protocolos de red y comunicaciones en que se ejecutarán. De esta manera se ofrece una mejor relación costo/rendimiento que pasa por el desarrollo de aplicaciones más complejas, en menos tiempo.
La función del middleware en el contexto de los data warehouse es la de asegurar la conectividad entre todos los componentes de la arquitectura de un almacén de datos.
Diseño de un almacén de datos
Para construir un Data Warehouse se necesitan herramientas para ayudar a la migración y a la transformación de los datos hacia el almacén. Una vez construido, se requieren medios para manejar grandes volúmenes de información. Se diseña su arquitectura dependiendo de la estructura interna de los datos del almacén y especialmente del tipo de consultas a realizar. Con este criterio los datos deben ser repartidos entre numerosos data marts. Para abordar un proyecto de data warehouse es necesario hacer un estudio de algunos temas generales de la organización o empresa, los cuales se describen a continuación:
- Situación actual de partida.- Cualquier solución propuesta de data warehouse debe estar muy orientada por las necesidades del negocio y debe ser compatible con la arquitectura técnica existente y planeada de la compañía.
- Tipo y características del negocio.- Es indispensable tener el conocimiento exacto sobre el tipo de negocios de la organización y el soporte que representa la información dentro de todo su proceso de toma de decisiones.
- Entorno técnico.- Se debe incluir tanto el aspecto del hardware (mainframes, servidores, redes,...) así como aplicaciones y herramientas. Se dará énfasis a los Sistemas de soporte a decisiones (DSS), si existen en la actualidad, cómo operan, etc.
- Expectativas de los usuarios.- Un proyecto de data warehouse no es únicamente un proyecto tecnológico, es una forma de vida de las organizaciones y como tal, tiene que contar con el apoyo de todos los usuarios y su convencimiento sobre su bondad.
- Etapas de desarrollo.- Con el conocimiento previo, ya se entra en el desarrollo de un modelo conceptual para la construcción del data warehouse.
- Prototipo.- Un prototipo es un esfuerzo designado a simular tanto como sea posible el producto final que será entregado a los usuarios.
- Piloto.- El piloto de un data warehouse es el primero, o cada uno de los primeros resultados generados de forma iterativa que se harán para llegar a la construcción del producto final deseado.
- Prueba del concepto tecnológico.- Es un paso opcional que se puede necesitar para determinar si la arquitectura especificada del data warehouse funcionará finalmente como se espera.
Almacén de datos espacial
Almacén de datos espacial es una colección de datos orientados al tema, integrados, no volátiles, variantes en el tiempo y que añaden la geografía de los datos, para la toma de decisiones. Sin embargo la componente geográfica no es un dato agregado, sino que es una dimensión o variable en la tecnología de la información, de tal manera que permita modelar todo el negocio como un ente holístico, y que a través de herramientas de procesamiento analítico en línea (OLAP), no solamente se posea un alto desempeño en consultas multidimensionales sino que adicionalmente se puedan visualizar espacialmente los resultados.
El almacén de datos espacial forma el corazón de un extensivo Sistema de Información Geográfica para la toma de decisiones, éste al igual que los SIG, permiten que un gran número de usuarios accedan a información integrada, a diferencia de un simple almacén de datos que está orientado al tema, el Data warehouse espacial adicionalmente es Geo-Relacional, es decir que en estructuras relacionales combina e integra los datos espaciales con los datos descriptivos. Actualmente es geo-objetos, esto es que los elementos geográficos se manifiestan como objetos con todas sus propiedades y comportamientos, y que adicionalmente están almacenados en una única base de datos Objeto-Relacional. Los Data Warehouse Espaciales son aplicaciones basadas en un alto desempeño de las bases de datos, que utilizan arquitecturas Cliente-Servidor para integrar diversos datos en tiempo real. Mientras los almacenes de datos trabajan con muchos tipos y dimensiones de datos, muchos de los cuales no referencian ubicación espacial, a pesar de poseerla intrínsecamente, y sabiendo que un 80% de los datos poseen representación y ubicación en el espacio, en los Data warehouse espaciales, la variable geográfica desempeña un papel importante en la base de información para la construcción del análisis, y de igual manera que para un Data warehouse, la variable tiempo es imprescindible en los análisis, para los Data warehouse espaciales la variable geográfica debe ser almacenada directamente en ella.
Ventajas e inconvenientes de los almacenes de datos
Ventajas
Hay muchas ventajas por las que es recomendable usar un almacén de datos. Algunas de ellas son:
- Los almacenes de datos hacen más fácil el acceso a una gran variedad de datos a los usuarios finales
- Facilitan el funcionamiento de las aplicaciones de los sistemas de apoyo a la decisión tales como informes de tendencia', por ejemplo: obtener los ítems con la mayoría de las ventas en un área en particular dentro de los últimos dos años; informes de excepción, informes que muestran los resultados reales frente a los objetivos planteados a priori.
- Los almacenes de datos pueden trabajar en conjunto y, por lo tanto, aumentar el valor operacional de las aplicaciones empresariales, en especial la gestión de relaciones con clientes.
Inconvenientes
Utilizar almacenes de datos también plantea algunos inconvenientes, algunos de ellos son:
- A lo largo de su vida los almacenes de datos pueden suponer altos costos. El almacén de datos no suele ser estático. Los costos de mantenimiento son elevados.
- Los almacenes de datos se pueden quedar obsoletos relativamente pronto.
- A veces, ante una petición de información estos devuelven una información subóptima, que también supone una pérdida para la organización.
- A menudo existe una delgada línea entre los almacenes de datos y los sistemas operacionales. Hay que determinar qué funcionalidades de estos se pueden aprovechar y cuáles se deben implementar en el data warehouse, resultaría costoso implementar operaciones no necesarias o dejar de implementar alguna que sí vaya a necesitarse.
Véase también
- Administración basada en la relación con los clientes
- Almacén de datos espacial
- Almacén operacional de los datos
- Data mart
- Esquema de la estrella
- Esquema del copo de nieve
- Extracción, transformación y carga
- Inteligencia empresarial
- Minería de datos espacial
- Minería de datos
- Procesamiento analítico en línea (OLAP), Cubos OLAP
- Procesamiento de transacciones a través de una red (OLTP)
- Sistema de gestión de base de datos
- Sistemas de soporte a decisiones
- Sistemas de información ejecutiva
- Tabla de hechos
- Tabla de dimensión
- Cuadro de mando integral
- Modelo de base de datos
Notas y referencias
- ↑ Bill Inmon en la Wikipedia en inglés
- ↑ Ralph Kimball en la Wikipedia en inglés.
- Ganczarski, Joe. Data Warehouse Implementations: Critical Implementation Factors Study. VDM Verlag, 2009. ISBN 3-639-18589-7, ISBN 978-3-639-18589-8
- Pyle, Dorian. Business Modeling and Data Mining. Morgan Kaufmann, 2003. ISBN 1-55860-653-X
Enlaces externos
- La diferencia entre transaccional y analítico Explicación no-técnica de Business Intelligence, desde un enfoque de negocio (en español)
- Definición alternativa y complementaria de Data warehouse Desde un punto de vista diferente, indicando más a fondo su relación con el ETL o los datamarts
- Manual de Business Intelligence (en español)
Categorías:- Terminología informática
- Bases de datos
- Sistemas de Información Geográfica
Wikimedia foundation. 2010.