- Traducción automática
-
La traducción automática (TA), también llamada MT (del inglés Machine Translation), es un área de la lingüística computacional que investiga el uso de software para traducir texto o habla de un lenguaje natural a otro. En un nivel básico, la traducción por computadora realiza una sustitución simple de las palabras atómicas de un lenguaje natural por las de otro. Por medio del uso de corpora lingüísticos se pueden intentar traducciones más complejas, lo que permite un manejo más apropiado de las diferencias en la Tipología lingüística, el reconocimiento de frases, la traducción de expresiones idiomáticas y el aislamiento de anomalías.
Contenido
Visión General
Los sistemas de traducción actuales permiten establecer parámetros (por ejemplo, limitando el rango de sustituciones permitidas) de acuerdo con el dominio o la profesión en la que se hace la traducción, lo que efectivamente mejora el resultado. Esta técnica es particularmente útil en campos donde se emplea un lenguaje formal o basado en formularios, como los reportes del tiempo y los documentos legales o administrativos, pero su uso no es viable en la traducción de conversaciones u otros textos menos estandarizados.
En las últimas décadas ha habido un fuerte impulso en el uso de técnicas estadísticas para el desarrollo de sistemas de traducción automática. Para la aplicación de estas técnicas a un par de lenguas dado, se requiere la diponibilidad de un corpus paralelo para dicho par. Mediante este corpus se estiman parámetros de sendos modelos estadísticos que establecen la probabilidad con la que ciertas palabras son susceptibles de traducirse por otras, así como las posiciones más probables que tienden a ocupar las palabras de la lengua destino en función de las palabras correspondientes de la frase origen. El atractivo de estas técnicas radica en que el desarrollo de un sistema para un par de lenguas dado puede hacerse de manera muy automática, con una muy reducida necesidad de trabajo experto por parte de especialistas en lingüística.
La intervención humana puede mejorar la calidad de la salida: por ejemplo, algunos sistemas pueden traducir con mayor exactitud, si el usuario ha identificado previamente las palabras que corresponden a nombres propios. Con la ayuda de estas técnicas, la traducción por computadora ha mostrado ser un auxiliar útil para los traductores humanos. Sin embargo, y aún cuando en algunos casos pueden producir resultados utilizables «tal cual», los sistemas actuales son incapaces de producir resultados de la misma calidad que un traductor humano, particularmente cuando el texto a traducir usa lenguaje coloquial o familiar.
En esta dirección, recientemente están cobrando especial interés las técnicas estadísticas de traducción asistida basadas en una aproximación interactiva-predictiva, en la que el computador y el traductor humano trabajan en estrecha colaboración mutua. Tomando como base el texto fuente a traducir, el sistema ofrece sugerencias sobre posibles traducciones a la lengua destino. Si alguna de estas sugerencias es aceptable, el usuario la selecciona y, en caso contrario, corrige lo necesario hasta obtener un fragmento correcto. A partir de este fragmento, el sistema produce mejores predicciones. El proceso continúa de esta manera hasta obtener una traducción completamente aceptable por el usuario. Según las evaluaciones realizadas con usuarios reales en el proyecto TransType-2, este proceso permite reducir considerablemte el tiempo y esfuerzo necesarios para obtener traducciones de calidad.
La traducción como problema
La traducción es hoy en día el principal cuello de botella de la sociedad de la información y su mecanización supone un importante avance frente al problema de la avalancha informativa y la necesidad de la comunicación translingüística.
Los primeros desarrollos informáticos reseñables se realizaron en el famoso ordenador Eniac en 1946. Entre los investigadores pioneros hay que citar a Warren Weaver, de la Fundación Rockefeller. Él fue quien dio a conocer públicamente la disciplina anticipando posibles métodos científicos para abordarla: el uso de técnicas criptográficas, la aplicación de los teoremas de Shannon y la utilidad de la estadística, así como la posibilidad de aprovechar la lógica subyacente al lenguaje humano y sus aparentes propiedades universales.
Actualidad
En la actualidad se obtienen altos niveles de calidad para la traducción entre lenguas romances (español, portugués, catalán o gallego, etc.). Sin embargo, los resultados empeoran ostensiblemente cuanto más tipológicamente alejadas sean las lenguas entre sí, como es el caso de la traducción entre español e inglés o alemán.
Otro factor muy influyente en la calidad es el grado de especialización de los sistemas de traducción, que mejoran en la medida en que se adecúan al tipo de texto y vocabulario que se vaya a traducir. Un sistema que se especialice en la traducción de partes meteorológicos conseguirá altas cotas de calidad incluso para traducir textos entre lenguas tipológicamente muy dispares, pero será inservible para abordar, por ejemplo, crónicas deportivas o financieras.
Traducir es una de las artes más elevadas y que requiere más talento y dedicación. No basta sólo con sustituir una palabra por otra, sino que también se ha de ser capaz de reconocer todas las palabras de una frase y la influencia que tienen las unas sobre las otras. Los lenguajes humanos constan de morfología (la forma en que se construyen las palabras a partir de pequeñas unidades provistas de significado), sintaxis (la estructura de una frase) y semántica (el significado). Hasta el texto más simple puede estar plagado de ambigüedades. También hay que considerar cuestiones de estilo y de discurso o pragmáticas.
Sin embargo, hay métodos estadísticos que realizan traducciones sin reparar en cuestiones gramaticales. En la actualidad la tendencia es a integrar todo tipo de metodologías: lingüísticas, estadísticas, u otras, a la base de datos de un corpus.
Historia de la traducción automática
La idea de la traducción automática puede remontarse al siglo XVII. En 1629, René Descartes propuso un lenguaje universal, con las ideas equivalentes en lenguas diferentes que comparten un mismo símbolo. En la década de 1950, el experimento de Georgetown (1954) involucraba una traducción totalmente automática de más de sesenta sentencias del ruso al inglés. El experimento fue todo un éxito y marcó el comienzo de una era con una importante financiación para la investigación de tecnologías que permitiesen la traducción automática. Los autores afirmaban que en un plazo de tres a cinco años, la traducción automática sería un problema resuelto.
El mundo salía de una guerra mundial que en el plano científico había incentivado el desarrollo de métodos computacionales para descifrar mensajes en clave. A Weaver se le atribuye haber dicho "cuando veo un artículo escrito en ruso me digo, esto en realidad está en inglés, aunque codificado con extraños símbolos. ¡Vamos a decodificarlo ahora mismo!" (citado por Barr y Feigenbaum, 1981). No hace falta decir que tanto los ordenadores como las técnicas de programación de aquellos años eran muy rudimentarias (se programaba mediante el cableado de tableros en lenguaje máquina), por lo que las posibilidades reales de probar los métodos eran mínimas.
El progreso real fue mucho más lento. El financiamiento para las investigaciones se redujo considerablemente tras el informe de ALPAC (1966), a causa de que encontró que la investigación que había durado diez años no había cumplido sus expectativas. A partir de los finales de la década de 1980, el poder de la computación aumentó la potencia de cálculo y la hizo menos costosa, y fue demostrado mayor interés en modelos estadísticos para la traducción automática.
La idea de utilizar las computadoras digitales para la traducción de las lenguas naturales ya se propuso en 1946 por A. D. Booth y posiblemente también otros. El experimento de Georgetown no fue de ninguna manera la primera de estas aplicaciones. Se efectuó una demostración en 1954 con el equipo APEXC en la Birkbeck Collage (Universidad de Londres) de una traducción rudimentaria del inglés al francés. En ese momento, se publicaron varios trabajos de investigación sobre el tema, e incluso artículos en revistas populares (véase, por ejemplo Wireless World, Septiembre de 1955, Cleave y Zacharov). Una aplicación similar, también pionera en la Birkbeck Collage de aquel entonces, fue la lectura y la composición de textos en braille por la computadora. Un referente obligado para conocer con más detalle la evolución de la traducción automática es el académico británico John Hutchins, cuya bibliografía puede, ser consultada libremente en Internet. En el artículo principal se sigue el esquema simplificado de Johnatan Slocum, que aborda la historia de la TA por décadas.
Tipos de traducción automática
Si disponen de suficiente información, las traducciones automáticas pueden funcionar bastante bien, permitiendo que personas con una lengua materna determinada sean capaces de hacerse una idea de lo que ha escrito otra persona en su idioma. El problema principal reside en obtener la información adecuada para cada uno de los métodos de traducción.
Según su aproximación, los sistemas de traducción automática se pueden clasificar entre dos grandes grupos: los que se basan en reglas lingüísticas por una parte, y los que utilizan corpus textuales por otra.
Traducción automática basada en reglas
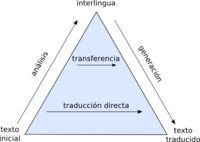 Esquema que muestra la relación entre los diferentes paradigmas de traducción automática basada en reglas.
Esquema que muestra la relación entre los diferentes paradigmas de traducción automática basada en reglas.
La traducción automática mediante reglas consiste en realizar transformaciones a partir del original, reemplazando las palabras por su equivalente más apropiado.
En general, en una primera fase se analizará un texto, normalmente creando una representación simbólica interna. Dependiendo de la abstracción de esta representación, también podemos encontrar diferentes grados: desde los directos, que básicamente hacen traducciones palabra por palabra, hasta interlingua, que utiliza una representación intermedia completa.
Transferencia
En la traducción por transferencia, el análisis del original juega un papel más importante, y da paso a una representación interna que es la que se utiliza como enlace para traducir entre idiomas distintos.
Lenguaje intermedio
La traducción automática a partir de un lenguaje intermedio es un caso particular de la traducción automática basada en reglas. El lenguaje original, por ejemplo un texto que debe ser traducido, es transformado a un lenguaje intermedio, cuya estructura es independiente a la del lenguaje original y a la del lenguaje final. El texto en el lenguaje final se obtiene a partir de la representación del texto en el lenguaje intermedio. En general a esta lengua intermedia se la llama "interlingua".
Traducción automática basada en corpus
La traducción automática a partir de un corpus lingüístico se basa en el análisis de muestras reales con sus respectivas traducciones. Entre los mecanismos que utilizan corpus se incluyen los métodos estadísticos y los basados en ejemplos.
Estadística
El objetivo de la traducción automática estadística es generar traducciones a partir de métodos estadísticos basados en corpus de textos bilingües, como por ejemplo las actas del parlamento europeo, que se encuentran traducidas en todos los idiomas oficiales de la UE. Si la existencia de estos corpus fuese mayor, se podrían conseguir resultados excelentes al traducir textos de ámbitos similares.
El primer programa de traducción automática estadística fue Candide, desarrollado por IBM. Hoy en día Google translate usa SYSTRAN, pero está trabajando en un método de traducción estadística para sus futuras traducciones automáticas. Recientemente han mejorado sus capacidades traductoras al añadir 200 billones de palabras de las Naciones Unidas que permitirán entrenar el sistema.
Aunque la exactitud de las traducciones, tanto las estadísticas como las que no, se ha incrementado con los años, la gran cantidad de posibilidades que tiene una palabra de ser traducida de un idioma a otro relega la traducción automática a un método que tan solo permite transmitir la idea esencial.
Basada en ejemplos
La traducción automática basada en ejemplos, se caracteriza por el uso de un corpus bilingüe como principal fuente de conocimiento en tiempo real. Es esencialmente una traducción por analogía y puede ser interpretada como una implementación del razonamiento por casos base empleado en el aprendizaje automático, que consiste en la resolución de un problema basándose en la solución de problemas similares.
Traducción automática basada en el contexto
La traducción automática basada en el contexto utiliza técnicas basadas en hallar la mejor traducción para una palabra fijándose en el resto de palabras que la rodean, básicamente este método se basa en tratar el texto en unidades de entre 4 y 8 palabras, de manera que se traduce cada una de ellas por su traducción al idioma destino y se eliminan las traducciones que han generado una "frase" sin sentido.
Luego se mueve la ventana una posición (palabra), retraduciendo la mayoría de ellas de nuevo y volviendo a filtrar dejando sólo las frases coherentes.
Se repite dicho paso para todo el texto. Y luego se pasa a concatenar los resultados de dichas ventanas de manera que se logre una única traducción del texto.
El filtrado que se realiza donde se decide si es una frase con sentido utiliza un corpus del lenguaje destino, donde se cuentan el número de apariciones de la frase buscada.
Es por tanto un método basado en ideas bastante simple que ofrece unos muy buenos resultados en comparación a otros métodos.
Como ventajas aporta también la facilidad de añadir nuevas lenguas. Ya que es sólo necesario:
- un buen diccionario, que puede ser cualquier versión comercial adaptada mediante reglas gramaticales para tener los verbos conjugados y los nombres/adjetivos con sus variaciones en número y género.
- un Corpus en el lenguaje destino, que se puede sacar por ejemplo de Internet. Sin que sea necesario traducir ninguna parte, como en los métodos estadísticos.
La traducción automática en España
La investigación en España ha pasado a través de tres etapas importantes. Desde 1985, se inicia la investigación con un interés repentino en España. Después de un año a su entrada a la Comunidad Europea. Fueron tres compañías transnacionales quienes financiaron la creación de varios grupos de investigación. IBM, Siemens y Fujitsu. Paradójicamente, 1992, que era el año de la celebración del 5to centenario del descubrimiento de América y de los juegos olímpicos también se llevaban a cabo en Barcelona. Primero IBM y luego Siemens, formaron en 1985 grupos de I+D en sus laboratorios de Madrid y Barcelona, liderados por Luis de Sopeña y Montserrat Meya, respectivamente. IBM utilizó el Centro de Investigación en inteligencia artificial de la Universidad Autónoma de Madrid como sede de un equipo especializado en lenguaje natural. Este equipo tomó parte primero en el diseño del prototipo Mentor, junto con otro centro IBM de Israel, y más tarde en la adaptación al espańol de LMT, sistema diseñado en el T.J. Watson Research Center de Estados Unidos. A tenor de las publicaciones del grupo en la revista Procesamiento del lenguaje natural, entre los años 1985 y 1992 trabajaron en los proyectos de IBM al menos los siguientes especialistas: Teo Redondo, Pilar Rodríguez, Isabel Zapata, Celia Villar, Alfonso Alcalá, Carmen Valladares, Enrique Torrejón, Begoña Carranza, Gerardo Arrarte y Chelo Rodríguez.
Por su parte, Siemens decidió acercar a Barcelona el desarrollo del módulo español de su prestigioso sistema Metal. Montserrat Meya, que hasta entonces había trabajado en los laboratorios centrales de Siemens en Munich, contactó con el filólogo e ingeniero Juan Alberto Alonso, y juntos formaron el núcleo de un equipo en el que luego participaría una interminable lista de colaboradores: Xavier Gómez Guinovart, Juan Bosco Camón, Begoña Navarrete, Ramón Fanlo, Clair Corbishley, Begońa Vázquez, etc. Después de 1992 el grupo dedicado a proyectos lingüísticos se constituyó en empresa independiente, Incyta. Tras un convenio con la Generalidad de Cataluña y la Universidad Autónoma de Barcelona, se desarrolló el módulo catalán, que es ahora su principal línea de actividad.
A finales de 1986 se crearon en Barcelona y Madrid dos nuevos grupos entre quienes se repartió el desarrollo de los módulos del sistema EUROTRA, financiado por la Comisión Europea. Ramón Cerdá reunió en la Universidad de Barcelona a un nutrido grupo de especialistas, integrado por, entre otros, Jesús Vidal, Juan Carlos Ruiz, Toni Badia, Sergi Balari, Marta Carulla y Nuria Bel. Mientras este grupo se ocupaba de las cuestiones de sintaxis y semántica, otro grupo se encargaba en Madrid de los aspectos de morfología y lexicografía, liderados por Francisco Marcos Marín. Colaboraban con él, entre otros, Antonio Moreno, Pilar Salamanca y Fernando Sánchez-León.
Un ańo más tarde, en 1987, se formó en los laboratorios de I+D de la empresa Fujitsu en Barcelona un quinto grupo para el desarrollo de los módulos de traducción al espańol del sistema japonés Atlas. Este grupo estaba liderado por el ingeniero Jorge Vivaldi y los filólogos José Soler, procedente de Eurotra, y Joseba Abaitua. Juntos crearán el embrión de un equipo al que más adelante se incorporaron Elisabet Cayuelas, Lluis Hernández, Xavier Lloré y Ana de Aguilar-Amat. La empresa interrumpió esta línea de investigación en 1992.
Otro grupo dedicado a la traducción automática por aquellos ańos fue el formado por Isabel Herrero y Elisabeth Nebot en la Universidad de Barcelona. Este grupo, tutelado por Juan Alberto Alonso, creó un prototipo de traducción árabe - español en colaboración con la Universidad de Túnez.
Está claro que la traducción automática fue el principal catalizador del nacimiento de la lingüística computacional en Espańa. No es casualidad que la Sociedad Española para el Procesamiento del Lenguaje Natural (SEPLN) se constituyera en 1983. Junto a Felisa Verdejo, otras dos personas se destacaron en su fundación, los citados Montserrat Meya y Luis de Sopeńa, quienes por aquel entonces lideraban, como se ha dicho, grupos de traducción automática. El tercer congreso de la asociación (entonces todavía bajo la denominación de Ťjornadas técnicasť) se celebró en julio de 1987 en la Universidad Politécnica de Cataluña, con dos platos fuertes sobre traducción automática: una conferencia de Sergei Nirenburg, entonces adscrito al Center for Machine Translation de la Universidad Carnegie Mellon, y una mesa redonda participada por Jesús Vidal y Juan Carlos Ruiz (de Eurotra), Luis de Sopeńa (de IBM), Juan Alberto Alonso (de Siemens), y el propio Nirenburg.
Algunos datos estadísticos constatan la relevancia de la traducción automática en la SEPLN entre los ańos 1987 y 1991. Durante aquellos ańos, de los 60 artículos publicados en la revista de la asociación, Procesamiento del lenguaje natural, 23 (más de un tercio) versaron sobre traducción automática. El nivel de participación refleja la relevancia de los grupos: ocho describen Eurotra, siete las investigaciones de IBM, cuatro Metal, de Siemens, y 3 Atlas, de Fujitsu. Sólo uno de los artículos publicados, de los 23, era ajeno a los cuatro proyectos estrella. Éste fue el presentado en el congreso de 1990 por Gabriel Amores, actual investigador del área de traducción automática, con los resultados de su investigación en el Centre for Computational Linguistics de Umist. Se han citado 35 personas y esta cifra da una idea de la actividad. En una estimación aproximada, se puede calcular que en 1989 la investigación en traducción automática contaba en España con un presupuesto anual de unos 200 millones de pesetas., una cifra que, por modesta que parezca, multiplica varias veces la cantidad que se maneja hoy en día en nuestro país, una década después.
Desde 1998, el Departamento de Lenguajes y Sistemas Informáticos de la Universidad de Alicante desarrolla sistemas de traducción automática entre lenguas románicas; estos sistemas están accesibles libremente por Internet: interNostrum, entre el español y el catalán; Traductor Universia, entre el español y el portugués, y, más recientemente, Apertium, un sistema de traducción automática de código abierto desarrollado en colaboración con un consorcio de empresas y universidades españolas, que actualmente traduce entre las lenguas del Estado español y otras lenguas románicas.
Recursos de la TA
Véase también
- Traducción asistida
- Traducción inmediata
- Inteligencia artificial
- Traducción automática estadística
- Traducción automática mediante lenguaje intermedio
- Traducción automática basada en el contexto
- Lista de herramientas de traducción automática
Bibliografía
- Pilar Hernández. 2002. En torno a la traducción automática internet.cervantes.es
- Joseba Abaitua. 2001. Introducción a la traducción automática (en 10 horas). Grupo DELi, Universidad de Deusto.
- Raquel Martínez. 2003. Principales problemas de la traducción automática. Universidad Juan Carlos I.
- Victoria López. 2002. Posibilidades y realidades de la Traducción Automática traducción.rediris.es | Rediris
Enlaces externos
Wikimedia foundation. 2010.